
英伟达BlackwellGPU代表了连年来最紧要的GPU微架构变革之一,但迄今枯竭详备的官方白皮书。
著名半导体连络机构SemiAnalysis历时数月,对Blackwell架构进行了系统性微基准测试,初次公开了该架构在AI职责负载下的硬件性能上限数据。
测试收尾走漏,Blackwell在张量中枢(TensorCore)微辞量、内存子系统领宽及新式2SMMMA辅导等重要维度上均接近表面峰值,但性能发扬高度依赖辅导体式设置,部分场景下存在明显的带宽瓶颈。这一发现对AI基础才能投资者和芯片采购方具有径直参考价值——架构后劲能否充分开释,取决于软件层面的密致调优。
SemiAnalysis已将关联基准测试代码库开源,测试所用B200节点由Nebius和Verda提供。连络团队同期通知,后续将推广至TPUPallas内核、TrainiumNKI内核及AMDCDNA4汇编的基准测试。
架构中枢变化:TMEM引入与2SMMMA
从Hopper到Blackwell,英伟达对MMA关联辅导的PTX轮廓层进行了多项热切调养。
最显耀的变化是引入了张量内存(TMEM)用于存储MMA累加器。在此前架构中,线程隐式捏有MMA运算收尾;Blackwell改为由软件在MMA作用域内显式管束TMEM,改变了线程与盘算收尾之间的悉数权关系。
与此同期,tcgen05操作当今由单一线程代表悉数这个词CTA(合作线程阵列)发出,而非此前Hopper架构中以warp或warpgroup为单元发出。这一变化在CuTeMMA原子中有径直体现:Blackwell使用ThrID=Layout,而Hopper使用ThrID=Layout。
Blackwell还引入了TPC作用域的TMA和MMA,维持两个协同CTA跨SM对试验tcgen05.mma,分享操作数,从而在裁减每个CTA分享内存带宽需求的同期,提供更高运算强度的MMA辅导。此外,该架构原生维持带微缩放的亚字节数据类型,并引入了集群启动收尾(CLC)手脚捏久化CTA内核中动态职责更正的硬件维持。
芯片物理布局:双Die架构与300周期跨Die蔓延
SemiAnalysis通过逆向工程妙技,滚球(中国)官网app揭示了B200芯片的物理拓扑结构。
连络团队讹诈PTX%%smid辅导,通过启动不同大小的集群来反向揣测SM到GPC(图形处理集群)的映射关系。收尾走漏,B200存在部分TPC独占逻辑GPC的情况,这些TPC从不与其他TPC协同更正。
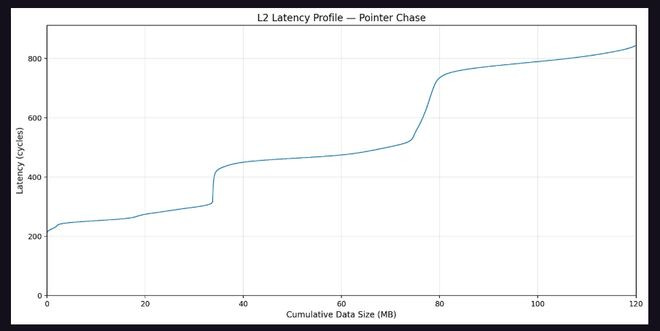
通过让每个SM遍历填满L2缓存的指针跟踪数组并测量各SM间的看望蔓延,连络团队构建了SM间距离矩阵。矩阵了了呈现出两组SM,平均L2看望蔓延差距卓绝300个时钟周期,对应的恰是两个Die之间的跨Die看望处分。
基于此,连络团队揣测B200的Die级TPC散布如下:
这一物理布局互异意味着,即便逻辑设置疏通的两块GPU,其物理SM散布也可能不同,组成潜在的性能非详情趣起首。
内存子系统:LDGSTS与TMA的性能边界
内存子系统测试聚焦于两类异步拷贝辅导:LDGSTS(异步拷贝)和TMA(张量内存加快器)。
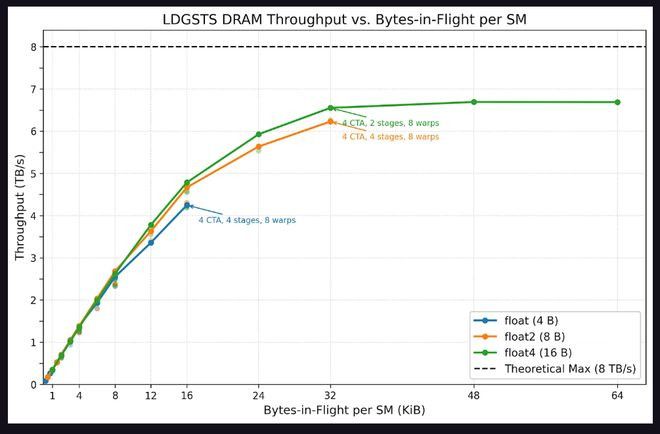
LDGSTS方面,测试遮盖了FlashInfer多头留心力(MHA)内核的典型设置。收尾走漏,IM体育官方网站LDGSTS内存微辞量在32KiB在途字节时富有,峰值约为6.6TB/s。16字节加载在疏通在途字节数下略优于8字节加载,且破钞更少试验资源。蔓延测试走漏,LDGSTS基线蔓延约为600纳秒,在途字节卓绝8KiB后蔓延接近翻倍,原因在于大皆线程因MIO(内存输入输出)节流而停滞。
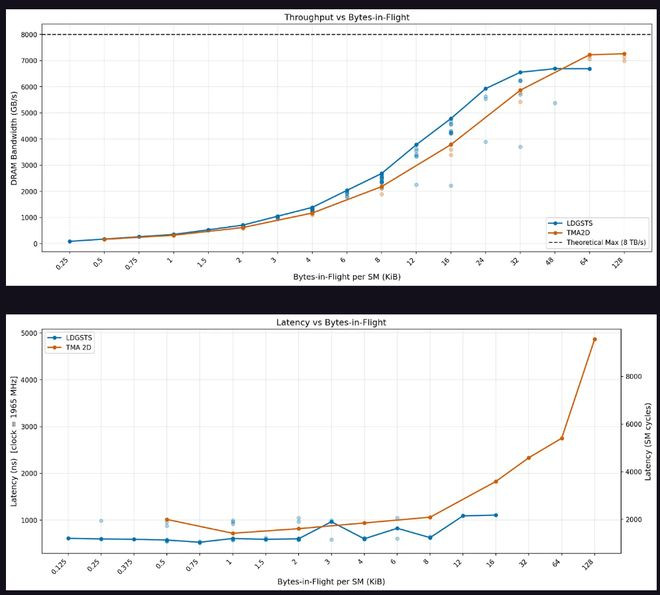
TMA方面,峰值微辞量的达到明显晚于LDGSTS。在低于32字节在途数据时,异步拷贝微辞量略优于TMA;卓绝该阈值后TMA追上并可捏续推广至128KiB。蔓延方面,在途数据低于12KiB时异步拷贝蔓延略低,超事后TMA蔓延大幅攀升。
TMA多播测试走漏,显式TMA多播可无缺铲除L2流量,已毕理思的"1/集群大小"L2字节比。隐式多播(各CTA孤独发出TMA加载至疏通数据)在灵验内存微辞量上与显式多播非常,但在卓绝64字节在途数据后,L2缓存流量削减成果驱动着落。
张量中枢肠能:体式依赖性显耀,2SMMMA已毕无缺弱推广
张量中枢测试是本次连络的中枢部分,收尾揭示了BlackwellMMA性能对辅导体式的高度敏锐性。
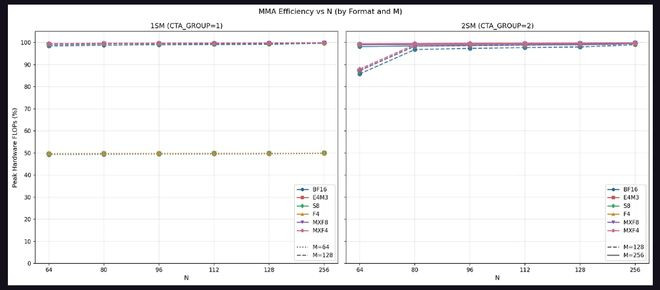
微辞量方面,关于1SMMMA,M=64的设置最高仅能达到表面峰值的50%,而M=128可接近100%。这阐发M=64仅讹诈了一半数据通路。关于2SMMMA,M=128在N=64时微辞量为峰值的90%,其余N尺寸均接近100%;M=256则在悉数设置下均看护接近100%的峰值微辞量,因为M=256等效于每SM处理M=128,可充分讹诈完整数据通路。
AB布局影响相似显耀。当两个输入矩阵均存储于分享内存(SS时势)时,M=128在N
2SMMMA已毕了无缺的弱推广,相干于1SMMMA在使用两倍盘算资源时得到2倍加快。在SS时势的小体式设置下,由于操作数B在两个SM间分片,以致出现卓绝2倍的加快。连络论断明确:应永恒使用给定SMEMtile尺寸下可用的最大辅导体式,以得到最高微辞量
蔓延方面,悉数设置下蔓延均随N从64增至128线性增长,N=256时出现高出。数据类型蔓延排序呈现律例性:S8
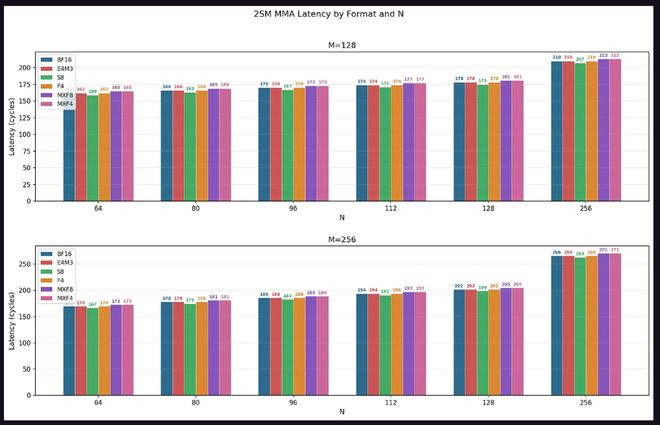
本色在途辅导数测试走漏IM体育官方网站,在典型内核使用的1至4条在途MMA辅导场景下,4条在途MMA的微辞量上限约为表面峰值的78%至80%,且1SMMMA比2SMMMA高出约5个百分点。
杏彩(XingCai)官网平台 备案号:
备案号: